The cogspace package allows to reproduce and reuse the multi-study task functional MRI decoding models presented in this preprint paper. Meaningful multi-study task-optimized networks can be downloaded here in Nifti format, and visualized here along with associated tags.
A new decoding approach
Our multi-study decoding model decodes mental states from statistical maps using a three-layer linear model that finds successive representations of brain maps that carry cognitive information. It finds task-optimized networks from which decoding generalize well across subjects.
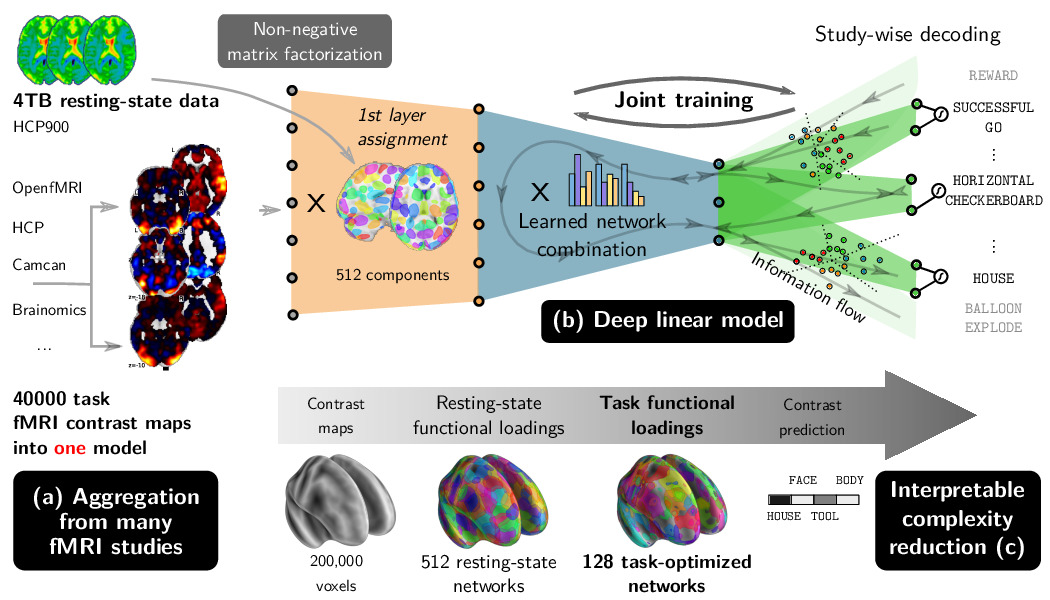
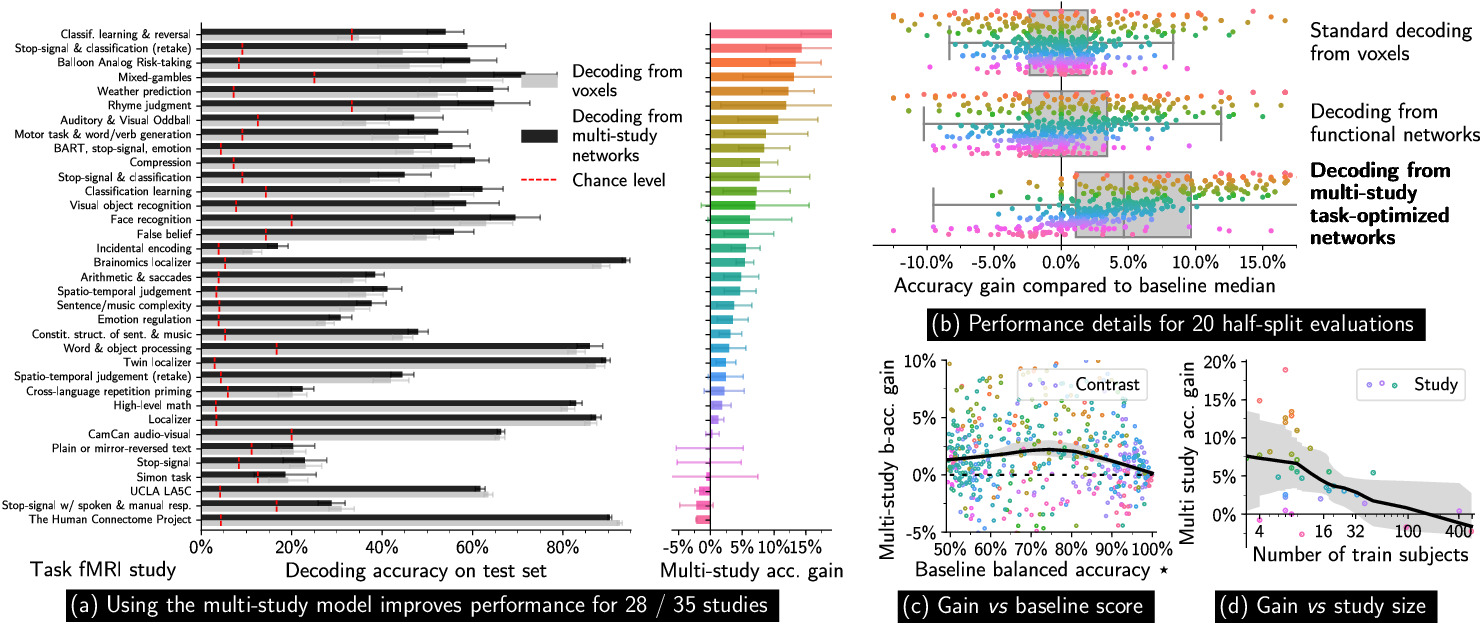
This approach allows to transfer cognitive information from one task fMRI study to another, and significantly increases decoding accuracy for many studies.
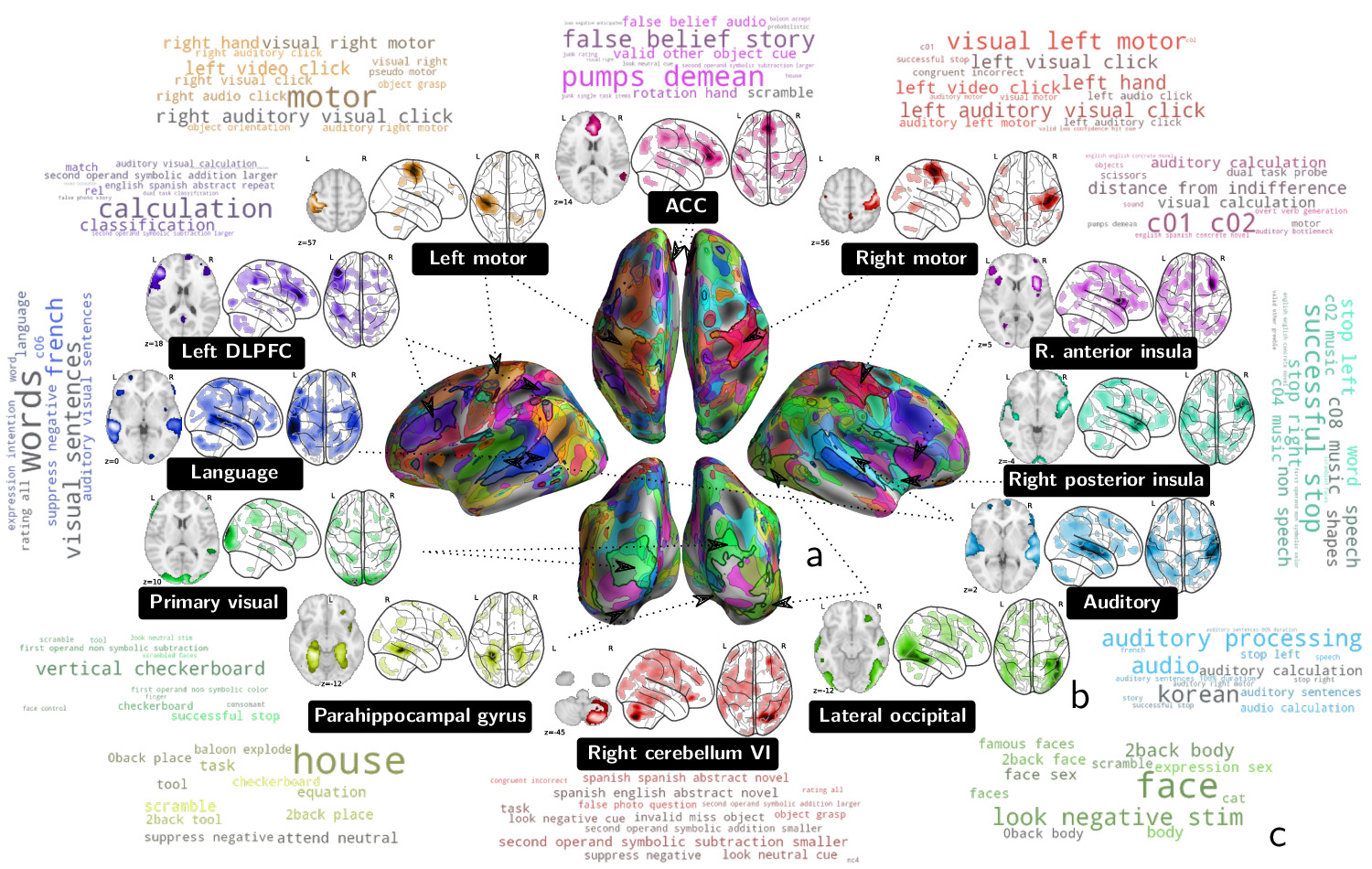
It also finds meaningful cognitive directions, readily associated to the labels they encourage to classify.
Downloading multi-study task optimized networks
Our approach allows to find functional networks optimized for general decoding. These networks can be reused in new studies for dimension reduction, with an expected boost in performance. Components trained on 35 studies (in compressed Nifti image format) can be found here.
Task/network correspondance
The typical tasks associated with each of these components can be visualized with word-clouds, as exemplified below.


Software
Cogspaces is tested with Python 3.6+.
Install
git clone github.com/arthurmensch/cogspaces
cd cogspaces
pip install -r requirements.txt
python setup.py install
Training and using multi-study models
exps/train.py allows to train and analyse multi-study models.
cd exps
python train.py
usage: train.py [-h] [-e {logistic,multi_study,ensemble}] [-s SEED] [-p]
[-j N_JOBS]
Perform traininig of a multi-study model using the fetchers provided by
cogspaces. Hyperparameters can be edited in the file.
optional arguments:
-h, --help show this help message and exit
-e {logistic,multi_study,ensemble}, --estimator {logistic,multi_study,ensemble}
estimator type
-s SEED, --seed SEED Integer to use to seed the model and half-split cross-
validation
-p, --plot Plot the results (classification maps, cognitive
components)
-j N_JOBS, --n_jobs N_JOBS
Number of CPUs to use
The estimators 'ensemble' and 'multi-study' use the models of the paper. The 'ensemble' estimator yields interpretable intermediary representations but is more costly to estimate.
A comparison grid between the factored model and decoding models from resting-state loadings can be run and analyzed with the following command:
cd exps
python grid.py
# Plot results
python compare.py
Note that the original figure of the paper compares the multi-study decoder to voxelwise, single-study decoder. As the input data for this baseline is large and requires to be downloaded and processed, we propose to reproduce a comparison with only reduced data as input.
Reduction of full statistical maps into data usable in train.py can be performed with the command:
cd exps
python reduce.py
Once obtained, a voxelwise decoder can be trained by changing the parameter config['data']['reduced'] = True in train.py.
API
Please check the docstrings in the package for a description of the API. In particular, the core scikit-learn like estimators are located in cogspaces.classification. Feel free to raise any issue on [github]https://github.com/arthurmensch/cogspaces.
Further data
We provide resting-state dictionaries for reducing statistical maps (the first layer of the model), as well as the reduced representation of the input statistical maps, and fetchers for the full statistical maps.
Resting-state dictionaries
The dictionaries extracted from HCP900 resting-state data can be download running
from cogspaces.datasets import fetch_dictionaries
dictionaries = fetch_dictionaries()
# dictionaries = {'components_64': ...}
They were obtained using the modl package. They may also be downloaded manually
- 64-components dictionary covering the whole brain
- 128-components dictionary covering the whole brain
- 453-components dictionary covering the grey-matter
- 128-components dictionary loadings over the 453-components dictionary
Reduced representation of the 35 studies
The loadings of the z-statistic maps over the 453-components dictionary can be loaded running
from cogspaces.datasets import load_reduced_loadings
Xs, ys = load_reduced_loadings()
print(Xs)
# {'archi': np.array(...), 'hcp': np.array(...)}
print(ys)
# {'archi': pd.DataFrame}, ...)
print(ys['archi'].columns)
# ['study', 'subject', 'task', 'contrast']
The full statistical maps are available on Neurovault, and may be downloaded using
from cogspaces.datasets import fetch_contrasts
df = fetch_contrasts('archi')
print(df.columns)
# ['z_map', 'study', 'subject', 'task', 'contrast']
df = fetch_contrasts('all')
License
Library and models are published under the Modified BSD License.
Publications
If the model or data proved useful, please consider to cite the following paper
- Mensch, A., Mairal, J., Thirion, B., & Varoquaux, G. (2018). Extracting Universal Representations of Cognition across Brain-Imaging Studies. arXiv: 1809.06035